Before opening a ticket, we strongly suggest understanding the difference between an incident and a service request, and knowing how tickets are prioritized and when they’re likely to be resolved.
Incident vs. Service Request
Incident
An Incident occurs when something malfunctions and a service stops working correctly. Simply put, an incident is when something was working before but isn’t anymore and it disrupts people from doing their tasks or disrupts the smooth operation of a business. When an incident happens, it can slow down progress and cause inconvenience. We prioritize fixing incidents based on how much they impact operations and how urgently they need attention.
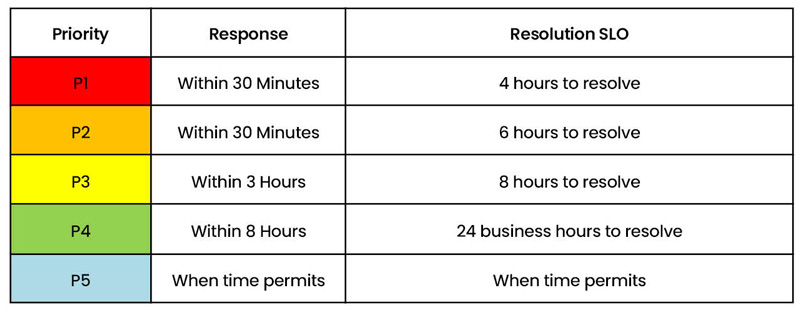
These priorities are categorized from P1 to P4, with P1 being the most urgent and P4 being the least urgent.
Examples: Printer stopped printing, laptop not working, or the entire network is down.
Service Request
A service request is simply when someone reaches out for assistance or information about something they require. It’s similar to requesting a service, such as having your password reset or gaining access to a computer program. These requests are typically not urgent matters and are managed in a standard manner to ensure they are addressed promptly and effectively.
Priority: Service requests are assigned one priority level, which is P5.
Examples: Granting access to a printer, requesting an additional printer, new hire setup, access termination, or install a new application.

How is my incident priority is being determined?
Priorities are determined based on the impact and the urgency.
Impact
This refers to how much a particular issue or problem affects the business or its operations. It’s about understanding the consequences of the issue. For example, if a critical system like the patient management software is down, it has a high impact because it directly affects the ability to provide services to patients. On the other hand, if a printer is malfunctioning in the break room, it might have a lower impact because it doesn’t directly affect critical operations.. Elements to measure impact:
- – Number of customers/users affected
- – Amount of lost revenue or incurred costs
- – Number of IT systems/services involved
High – Issue impacting core business function in multiple locations or multiple critical applications in a single location. Significant financial loss. Impacting all staff. Impact to all patients. Significant reputational impact.
Example 1: Open Dental Middle Tier Server is down impacting 3 Clinics on Open Dental.
Example 2: Network Switch in a clinic is down causing PMS, internet, and Phone outage.

Medium – Issue impacting a single critical application causing a work slowdown for a few people but typically doesn’t involve a full outage. Significant financial loss.
Example 1: Accounting software is not working.
Example 2: PMS is down.
Low – Issue is impacting a user with a single non-critical app or hardware. This is typically something that is more of an annoyance than a work stoppage.
Example: A single user is unable to print.
Urgency
This is about how quickly a particular issue needs to be resolved. It’s related to time sensitivity. For example, if there’s a security breach in the network, it’s urgent because it needs immediate attention to prevent further damage. However, if there’s a minor software glitch that’s not affecting anyone’s work, it might not be as urgent. The three levels of urgency are:
High – The damage caused by the Incident increases rapidly. Work that cannot be completed by staff is highly time sensitive. No workaround is available.
Medium – The damage caused by the Incident increases considerably over time. Workaround is available but not sustainable.

Low – The damage caused by the Incident only marginally increases over time. Work that cannot be completed by staff is not time sensitive. Workaround is available.
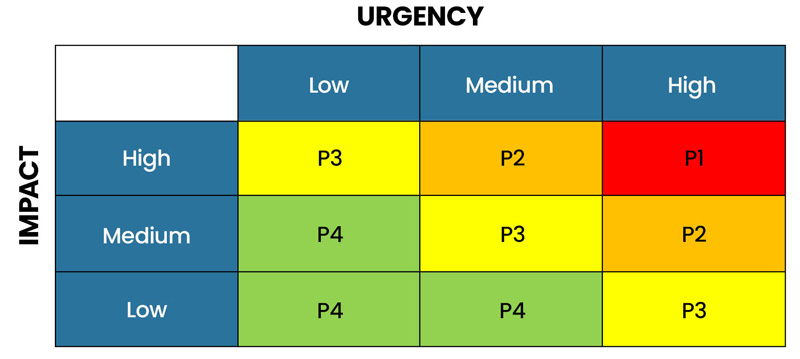
Priority Grid
Now, when you combine impact and urgency, you get a clearer picture of which IT issues should be addressed first. Correlating impact and urgency can be easily done in a simple matrix, and it can help determine service levels and track performance measures when treating incidents.
So, when should I expect to have my ticket resolved?